|
I have already obtained my Ph.D degree from the Department of Computer Science and Technology at Northeastern University, China. I work at Natural Language Processing Lab under the supervision of Prof. Tong Xiao and Prof. Jingbo Zhu. I received my bachelor degree in 2017 from Northeastern University, majoring in Computer Science and Technology, and my master in 2020 from Northeastern University, majoring in Computer Software and Theory. My research interests include complex architecture modeling, deep transformers, multimodal modeling, and machine learning. Currently, I am focusing on large language models, such as prompt engineering via deliberation (DTG), evolutionary algorithms-based prompt search (EvoPrompt), foundation models (PCformer and its subsequent work), and DPO improvements (temporal-decay based DPO). Please feel free to contact me if you are interested in my work or have any questions you'd like to discuss! Email / Resume / Google Scholar / Github |

|
|
My primary focus lies within the domain of sequence generation tasks, encompassing fields such as machine translation, abstractive summarization, and more. Presently, my central research objective is the development of parameter-efficient backbones for natural language processing tasks, striving towards models that achieve superior performance with a minimized computational footprint. While, I am also interested in designing highly effective prompts for large language model to activate the underlying abilities. |
|
Ruichen Shao*, Bei Li*, Gangao Liu, Yang Chen, Xiang Zhou, Jingang Wang, Xunliang Cai and Peng Li Forty-Second International Conference on Machine Learning (ICLR), 2025 [pdf] / [code] In this work, we propose an enhanced preference optimization method that incorporates a temporal decay factor controlled by a gamma parameter. This dynamic weighting mechanism adjusts the influence of each reward based on its position in the sequence, prioritizing earlier tokens that are more critical for alignment. By adaptively focusing on more relevant feedback, our approach mitigates overfitting to less pertinent data and remains responsive to evolving human preferences. Experimental results on several benchmarks show that our approach consistently outperforms vanilla DPO by 5.9-8.8 points on AlpacaEval 2 and 3.3-9.7 points on Arena-Hard across different model architectures and sizes. Furthermore, additional experiments on mathematical and reasoning benchmarks (MMLU, GSM8K, and MATH) confirm that our method enhances performance without compromising general capabilities. |
|
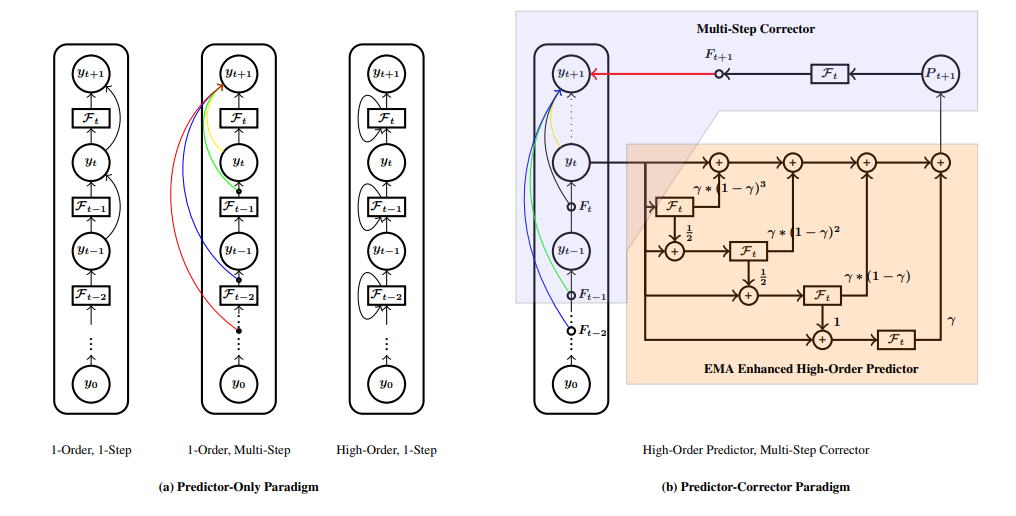
Bei Li, Tong Zheng, Rui Wang, Jiahao Liu, Qingyan Guo, Junliang Guo, Xu Tan, Tong Xiao, Jingbo Zhu, Jingang Wang and Xunliang Cai The Thirty-Eighth Annual Conference on Neural Information Processing Systems (Neurips), 2024 [pdf] / [code] In this work, we present a series of advanced explorations of Transformer architecture design to minimize the error compared to the true ``solution.'' First, we introduce a predictor-corrector learning framework to minimize truncation errors, which consists of a high-order predictor and a multistep corrector. Second, we propose an exponential moving average-based coefficient learning method to strengthen our higher-order predictor. Extensive experiments on large-scale machine translation, abstractive summarization, language modeling, and natural language understanding benchmarks demonstrate the superiority of our approach. On the WMT'14 English-German and English-French tasks, our model achieved BLEU scores of 30.95 and 44.27, respectively. Furthermore, on the OPUS multilingual machine translation task, our model surpasses a robust 3.8B DeepNet by an average of 2.9 SacreBLEU, using only 1/3 parameters. Notably, it also beats LLama models by 5.7 accuracy points on the LM Harness Evaluation. |

|
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, Yujiu Yang The Twelfth International Conference on Learning Representations (ICLR), 2024 [pdf] / [code] In this paper, we introduce EvoPrompt, a novel framework for optimizing discrete prompts in Large Language Models (LLMs) using evolutionary algorithms (EAs). This method effectively integrates the language processing strengths of LLMs with the optimization capabilities of EAs, eliminating the need for gradients or parameters. EvoPrompt starts with a set of prompts and evolves them through LLM-based iterations, showing significant improvement over human-crafted prompts and existing automated methods by up to 25% and 14% respectively. Tested on nine datasets across language understanding and generation tasks with both closed- and open-source LLMs like GPT-3.5 and Alpaca, EvoPrompt demonstrates the potential for further research in combining LLMs with traditional algorithms. |

|
Bei Li*, Yuxin Zuo*, Chuanhao Lv, Tong Zheng, Tong Xiao and Jingbo Zhu The 2023 Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP), 2023 [pdf] / [code] Building on our previous work presented at ACL 2022, this study aims to enhance cross-modal interaction in language models. We propose a new approach that generates Visual Question Answering (VQA)-style pairs from text and incorporates probing signals during the training process. Our extensive experiments confirm that this multi-task learning framework effectively alleviates the issue of insufficient cross-modal interaction, offering a significant advancement over our prior work. |

|
Yuhao Zhang, Chen Xu, Bei Li, Tong Xiao and Jingbo Zhu The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023 [pdf] / [code] In this work, we find that the textual encoder primarily facilitates cross-modal conversion, but the presence of noise in speech impedes the consistency between text and speech representations. Furthermore, we propose an improved multi-task learning (IMTL) approach for the ST task, which bridges the modal gap by mitigating the difference in length and representation. |

|
Bei Li, Rui Wang, Junliang Guo, Kaitao Song, Xu Tan, Hany Hassan, Arul Menezes, Tong Xiao, Jiang Bian and JingBo Zhu In progress, comming soon. [pdf] / [code] We encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. |

|
Yongyu Mu, Abudurexiti Reheman, Zhiquan Cao, Yuchun Fan, Bei Li, Yinqiao Li, Tong Xiao, Chunliang Zhang and Jingbo Zhu 61th Annual Meeting of the Association for Computational Linguistics (Findings of ACL), 2023 [pdf] / [code] In-context learning (ICL) augments the capabilities of large language models (LLMs) in various downstream tasks by leveraging input and output exemplars. This paper explores the use of translation memory (TM) as a form of prompting to aid LLMs in machine translation tasks. Notably, the LLM's inherent ability to comprehend these prompts significantly bolsters the use of TM. Experimental results indicate that incorporating TM considerably enhances the translation proficiency of the LLM, elevating its BLEU score to levels commensurate with state-of-the-art neural machine translation systems. |
|
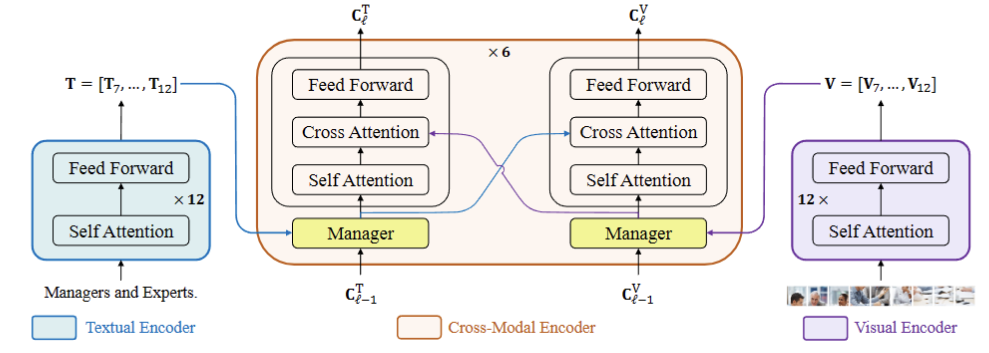
Xiao Xu, Bei Li, Chenfei Wu, Shao-Yen Tseng, Anahita Bhiwandiwalla, Shachar Rosenman, Vasudev Lal, Wanxiang Che and Nan Duan 61th Annual Meeting of the Association for Computational Linguistics (ACL, Oral), 2023 [pdf] / [code] We propose ManagerTower, a novel Vision-Language model architecture that gathers and combines the insights of pre-trained uni-modal experts at different levels. The managers introduced in each cross-modal layer can adaptively aggregate uni-modal semantic knowledge to facilitate more comprehensive cross-modal alignment and fusion. ManagerTower outperforms prior work. |
|
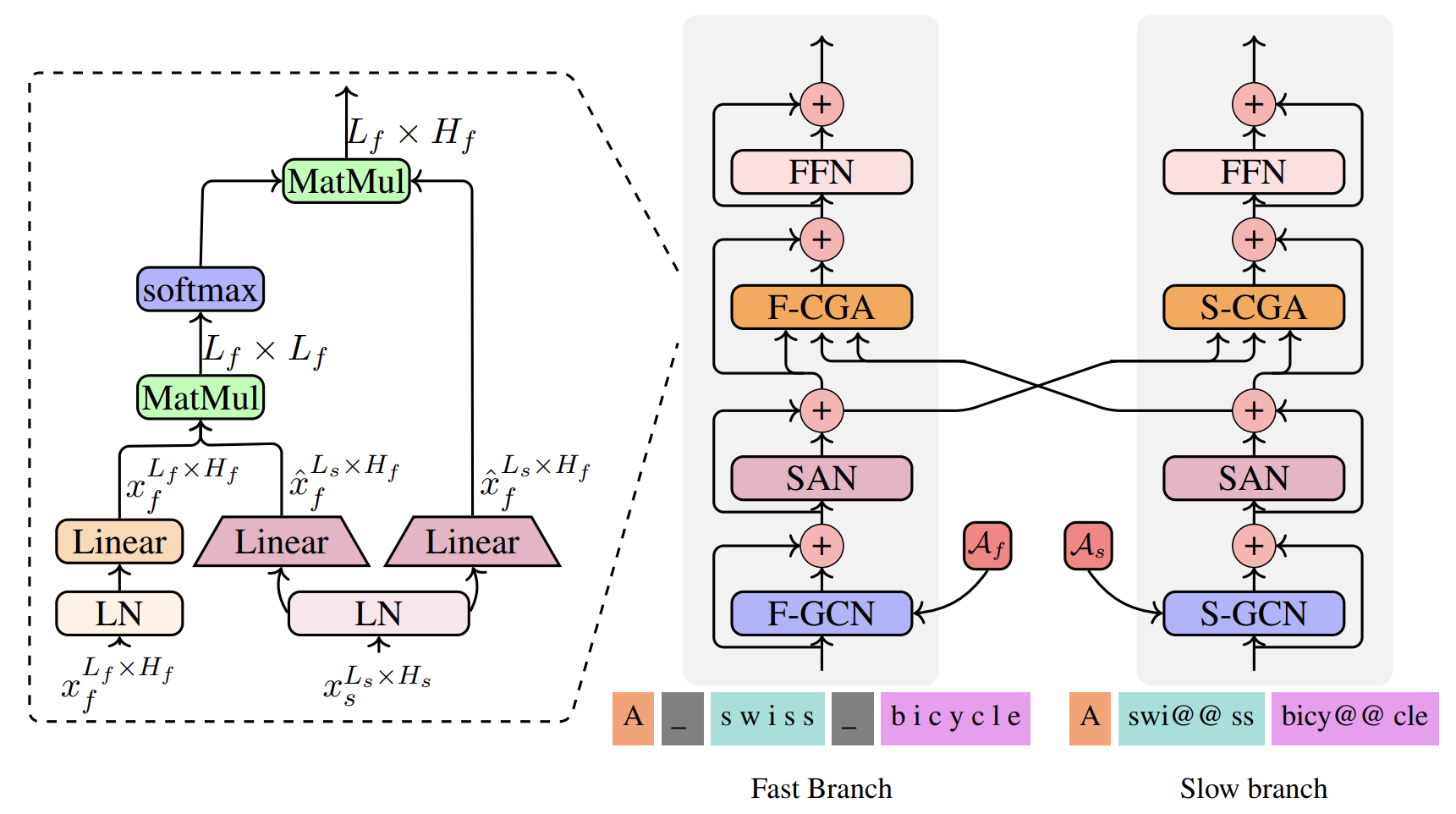
Bei Li, Yi Jing, Xu Tan, Zhen Xing, Tong Xiao and Jingbo Zhu 61th Annual Meeting of the Association for Computational Linguistics (Findings of ACL), 2023 [pdf] / [code] Building upon our previous ICML work, we refine the extraction of fine-grained character-level features by developing a multiscale Transformer model with a two-branch architecture. The Slow-Fast framework effectively mitigates the computational overhead associated with capturing long-term dependencies among character-level sequences, while employing a cross-granularity attention mechanism to learn interactions between the fast and slow branches. Comprehensive experiments conducted on multiple machine translation benchmarks attest to the efficacy of our proposed TranSFormer model. |
|
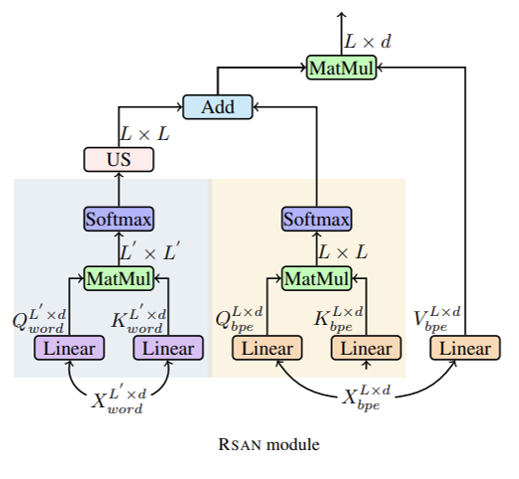
Bei Li, Tong Zheng, Yi Jing, Chengbo Jiao, Tong Xiaoand Jingbo Zhu International Conference on Machine Learning (ICML, Spotlight), 2022 [pdf] / [code] We re-define the concept of scale for NLP, including scales of sub-word, word and phrase. Our intention is to leverage the word boundaries and phrase-level prior knowledge to compensate for the sub-word features. Then we establish the relationships among different scales, resulting in builting a multiscale Transformer model. |

|
Bei Li, Chuanhao Lv, Zefan Zhou, Tao Zhou, Tong Xiao, Anxiang Ma and Jingbo Zhu 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022 [pdf] / [code] This work investigates the effect of vision features in multimodal machine translation (MMT) scenarios. We proposed three probing tasks to evaluate MMT systems which can help the following researchers. The main contribution is to reveal the importance of strong vision features. |
|
|
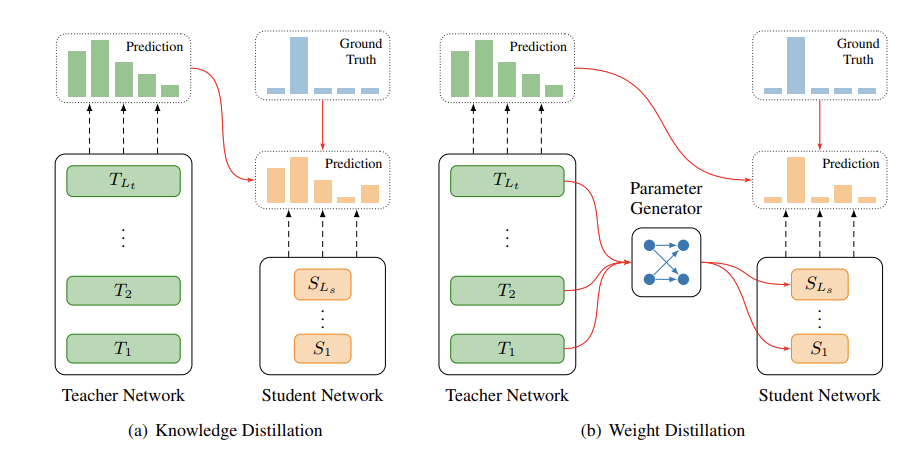
Bei Li, Quan Du, Tao Zhou, Yi Jing, Shuhan Zhou, Xin Zeng, Tong Xiao,and Jingbo Zhu 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022 [pdf] / [code] This work attempts to further enhance the standard sequence-level KD method by taking full advantage of the teacher parameters and generate the parameters for student. |
|
Ye Lin, Yanyang Li, Ziyang Wang, Bei Li, Quan Du, Tong Xiao, Jingbo Zhu 59th Annual Meeting of the Association for Computational Linguistics (ACL, Oral), 2021 [pdf] / [code] This work establishes the relationship between ODE and the design of Transformer architecture. We also redesign the Transformer architecture inspired by the lower truncation error achieved by high-order solvers in ODE. ODE Transformer can deliver much better translation performance within the same model capacity. Experimental results on three sequence generation tasks demonstrate the effectiveness. |

|
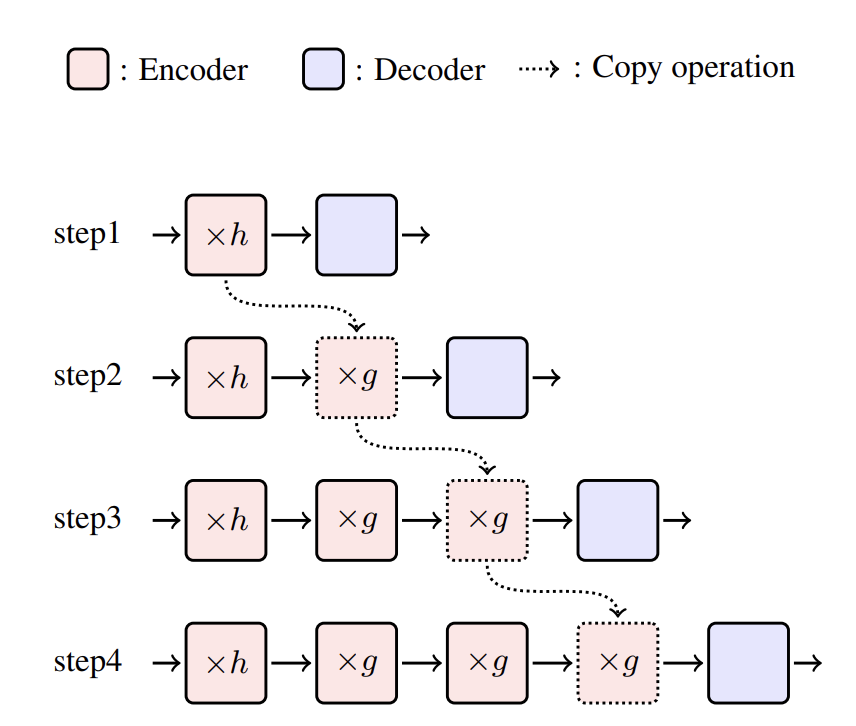
Bei Li, Ziyang Wang, Hui Liu, Quan Du, Tong Xiao, Chunliang Zhang, Jingbo Zhu Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI), 2021 [pdf] / [code] This work attempts to learn a light-weight translation model from a deep Transformer teacher network. It introduces a group-permutation based knowledge distillation method to compressing a strong deep Transformer teacher into a much shallower counterpart with a minor BLEU degradation. Furthermore, to enhance the performance of the teacher network, we also propose a skipping sub-layer regularization training method to randomly omit some sub-layers vertically. Both methods can be well applicable into the teacher training process. |
|
Bei Li, Ziyang Wang, Hui Liu, Yufan Jiang, Quan Du, Tong Xiao, Huizhen Wang, Jingbo Zhu The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020 [pdf] / [code] Deep Transformer systems have been widely investigated in the MT community recently. However, with the model going deeper, a crucial challenge is the huge memory cost and extremely long training time. We investigate the behavior of trained systems and find that adjacent layers behave similarly. Thus, we proposed a shallow-to-deep training method instead of learning from scratch which speeds up the training process up to 1.5 times with no loss in BLEU. |

|
Bei Li, Hui Liu, Ziyang Wang, Yufan Jiang, Tong Xiao, Jingbo Zhu, Tongran Liu, Changliang Li 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020 [pdf] / [code] We investigate a general-used multi-encoder framework on document-level machine translation task. It utilizes an additional context-encoder to capture the relationship between the current sentence and its contextual information. However, through specially designed context inputs, we find that the context-encoder acts more like a noise generator instead of encoding the contextual information, which is similar with dropout.Especially when we turn off the context-encoder during inference, there is even slight improvements in terms of BLEU score. |
|
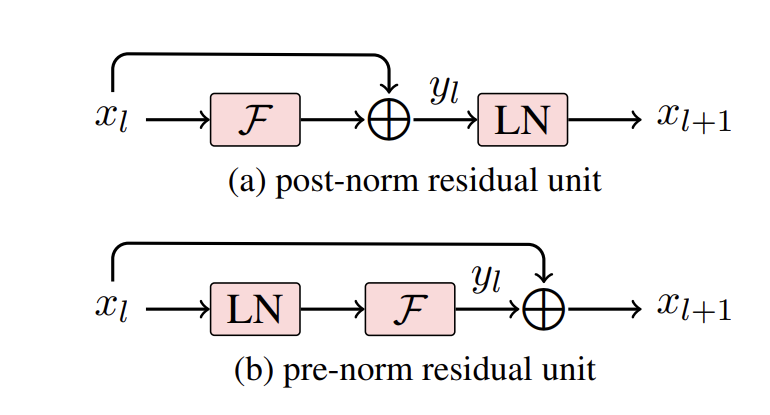
Qiang Wang, Bei Li, Tong Xiao, Jingbo Zhu, Changliang Li, Derek F Wong, Lidia S Chao 57th Annual Meeting of the Association for Computational Linguistics (ACL, Oral), 2019 [pdf] / [code] It studies deep encoders in Transformer and mathematically explains the importance of the location of layer normalization for deep models. It also proposes a novel connection schema to successfully train a 30-layer Transformer system, which is the deepest encoder at that time. While, it is one of the most high cited NMT papers. |

|
Bei Li, Yinqiao Li, Chen Xu, Ye Lin, Jiqiang Liu, Hui Liu, Ziyang Wang, Yuhao Zhang, Nuo Xu, Zeyang Wang, Kai Feng, Hexuan Chen, Tengbo Liu, Yanyang Li, Qiang Wang, Tong Xiao, Jingbo Zhu Fourth Conference on Machine Translation (WMT, Workshop of ACL), 2019 [pdf] / [code] It describes the submission of the NiuTrans systems for WMT2019 on both supervised and unsupervised tasks, including 13 language directions. This paper shows the details about model architectures, data augmentation methods, ensemble knowledge distillation and system combination strategies. |

|
Research Intern, MicroSoft Research Asia, Natural Language Computing
May. 2022 - Dec. 2022 Advisor: Chenfei Wu Text-to-Image Generation, Diffusion Models, Multimodal Modeling |
|
|
Research Intern, MicroSoft Research Asia, Machine Learning
Dec. 2022 - Nov. 2023 Advisor: Xu Tan, Rui Wang Machine Translation, Ordinary Differential Equation, Large Language Models |
|
© Bei Li | Last updated: Nov. 2023. |